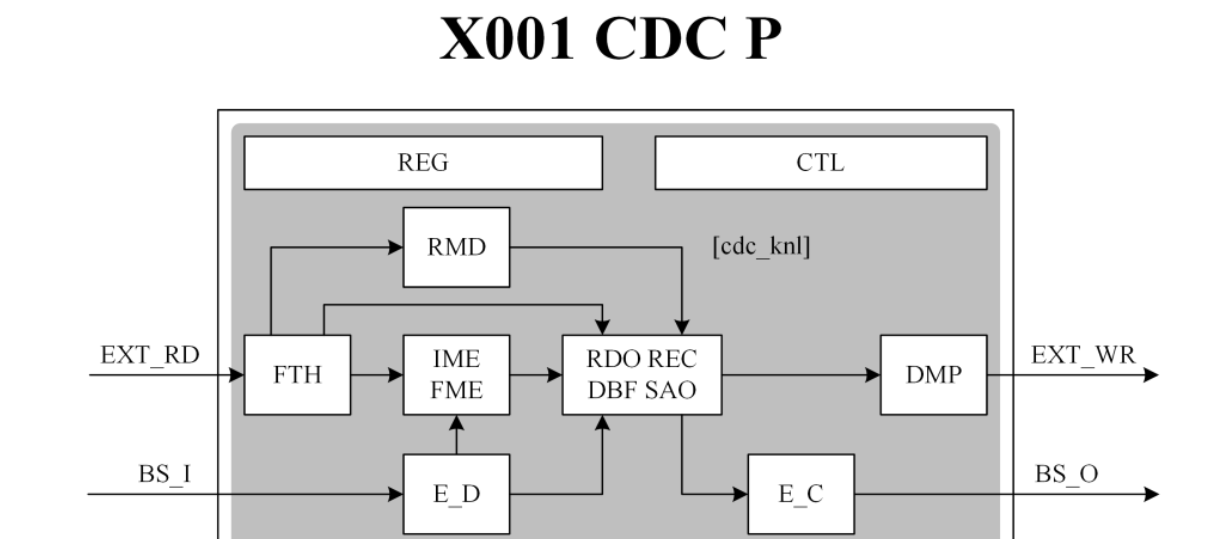
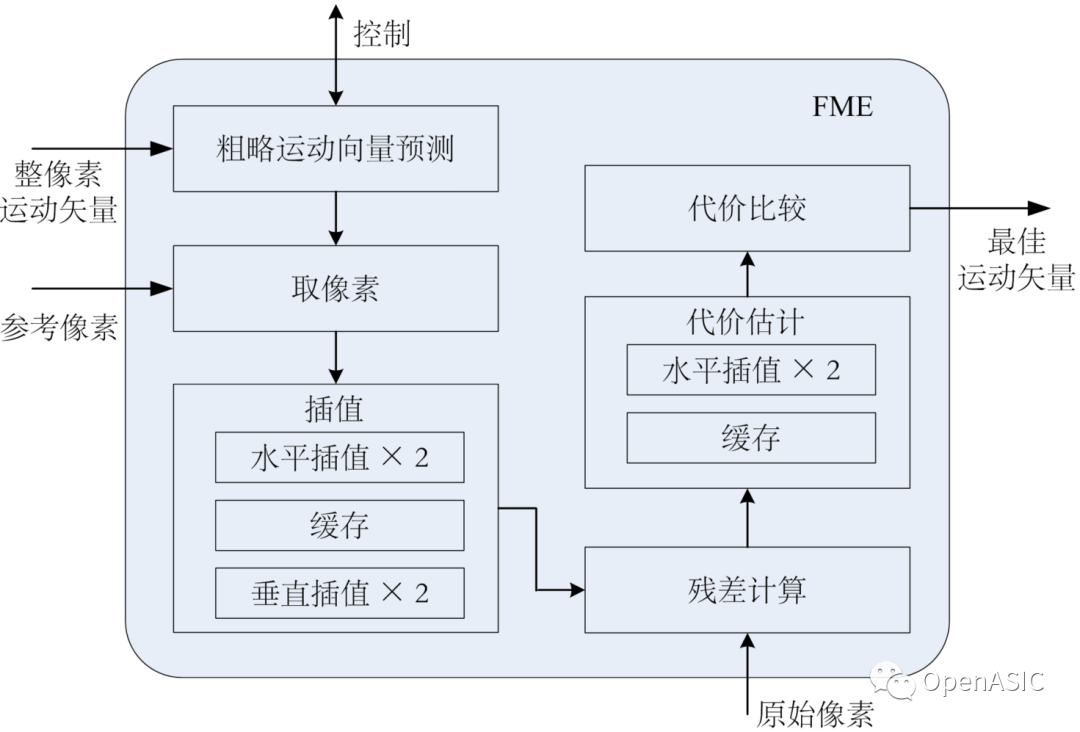
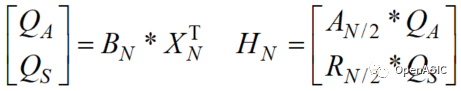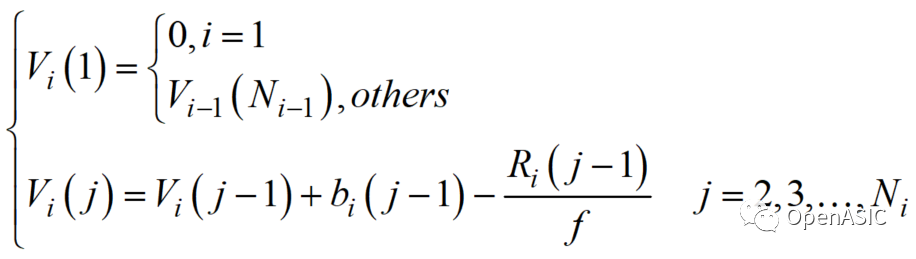視頻編解碼芯片設計原理----07 重建環路?
本系列主要介紹視頻編解碼芯片的設計,以HEVC視頻編碼標準為基礎,簡要介紹編解碼芯片的整體硬件架構設計以及各核心模塊的算法優化與硬件流水線設計。
本文給出了HEVC重建環路的相關背景知識,并在此基礎上分析了VLSI實現下重建環路所面臨的實際問題,并有針對地在模塊層次和架構層次對重建環路進行了優化。
概述
重建環路,指的是在重建的過程中,對于當前塊的處理必須依賴于前一塊的處理結果,導致預測、變換、量化、反量化、反變換和重建的這一系列過程成為了一條首尾相連的環路。變換是將空間域像素形式描述的圖像轉換至變換域,以變換系數的形式呈現。量化是在變換的基礎上對變換系數進一步處理,壓縮視頻信息量,減小視頻碼率。
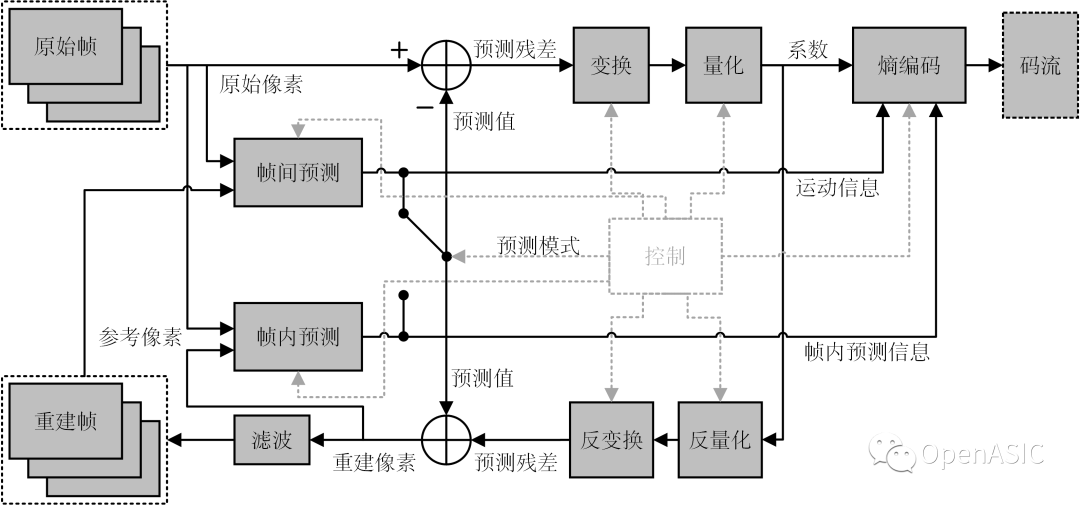
在HEVC 標準中,“重建環路”如下圖所示。其中,由預測像素和原始像素相減所得到的殘差像素被送往離散余弦變換(DCT)模塊和量化(Q)模塊,用以得到熵編碼(CABAC)模塊所需要的變換系數。與此同時,這些變換系數還被送往反量化(IQ)模塊和反變換(IDCT)模塊用以產生重建后的殘差和重建后的像素。
變換與反變換
將一維N個實數采樣值變換為N個變換域上的變換系數的過程稱為一維DCT。DCT變換是一個線性的可逆過程,將N個變換系數重構為N個實數采樣值的過程稱為逆DCT。二維N×M空間的DCT/IDCT變換定義為如下。
DCT的矩陣系數中包含實數,這種浮點DCT變換會引入浮點乘法計算,并且正變換與逆變換由于精度誤差可能產生偏移,因此H.264/AVC、AVS、HEVC等視頻編碼標準都采用了整數DCT變換。
4×4 的DCT 整數變換矩陣:
8×8 的DCT 整數變換矩陣:
DCT整數變換是對離散余弦變換的近似,具有可分離性、對稱性、遞歸性等特性。可分離性指二維變換可以通過兩次一維變換實現,即先對輸入數據做行(列)變換,然后對中間結果做列(行)變換。對稱性是指N階DCT整數變換矩陣中每一行元素具有對稱性:偶數行元素左右對稱,奇數行元素左右反對稱。遞歸性可以用8×8變換矩陣來舉例,可以看到,8×8變換矩陣的第0、2、4、6行的左半部分元素合起來形成的4×4矩陣,即為HEVC中的4×4變換矩陣。
量化與反量化
HEVC中的量化計算過程如下式所示。
反量化計算過程下式所示,其中裁剪的步驟確保了變換系數量化后的值保持16bit位寬。
其中參數Q和IQ的定義如下:
其他參數,如coeff代表經過二維整數離散余弦變換后的系數;level代表量化后的系數值;coeffQ代表反量化后的系數值。參數QP代表量化參數;B代表位深;N代表變換尺寸;M=log2(N)。
VLSI實現
設計考量
重建環路在硬件代價上和周期代價上都是HEVC編碼器的實現瓶頸。硬件代價直接來源于復雜的預測模式和32×32大小的DCT變換。周期代價則來源于棘手的數據依賴、PU模式的選擇和CU、PU、TU塊劃分的決定,提高對于單個TU/PU的處理速度對于重建環路來說是十分必要的。
變換與反變換
1D-DCT的計算過程可進行如下的分解
其中
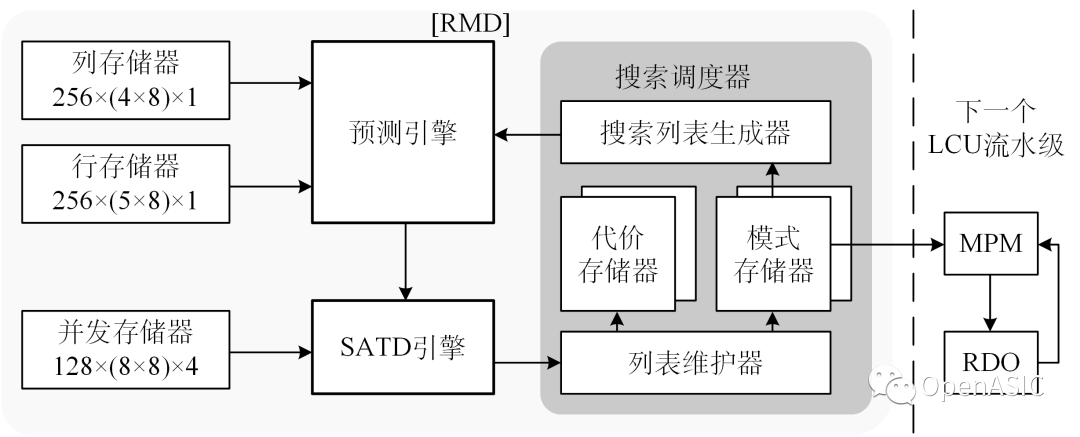
因此,N點1D-DCT的硬件實現可以分為四個基本矩陣向量積模塊,即BN*XNT模塊、AN/2*XN/2T模塊、RN/2*XN/2T模塊、PN*XNT模塊,由基本模塊可以實現高性能的1D-DCT變換。
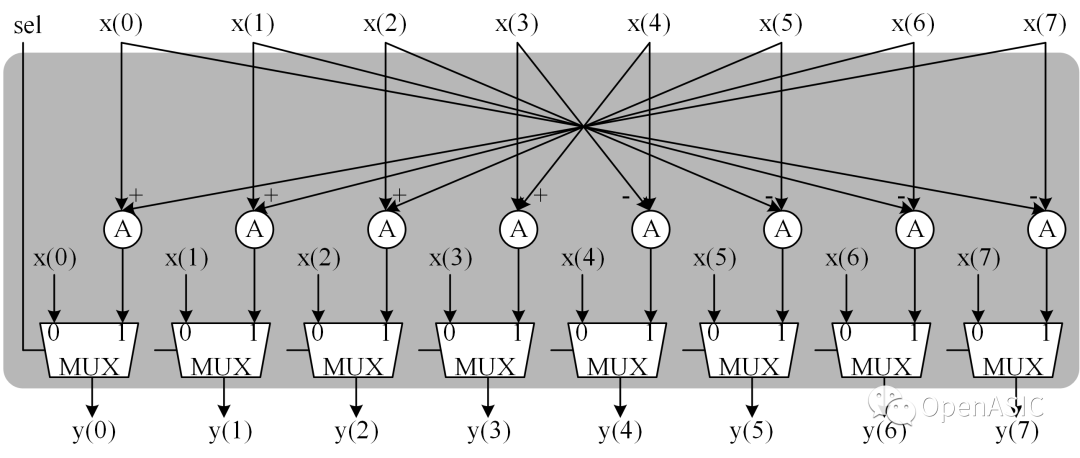
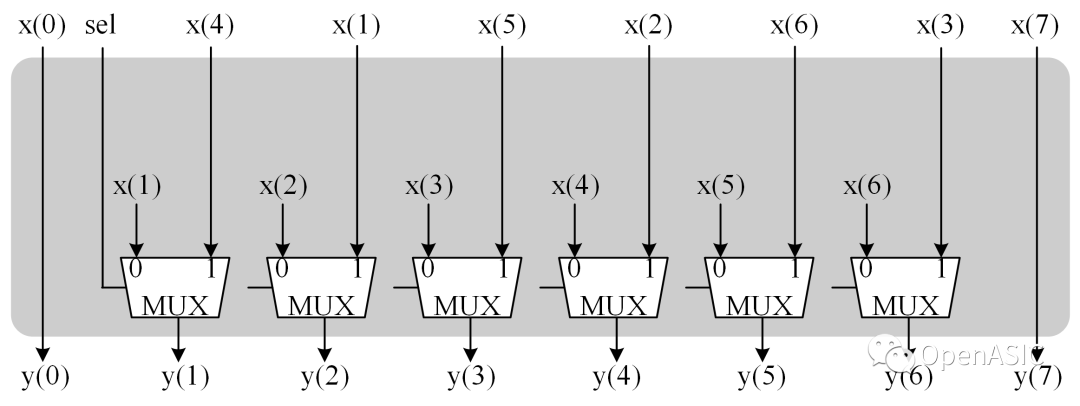
BN*XNT模塊的硬件設計以B8*X8T為例,如下圖所示。
AN/2*XN/2T模塊的硬件設計以A4*X4T為例,如下圖所示。
RN/2*XN/2T模塊的硬件設計以R4*X4T為例,如下圖所示。
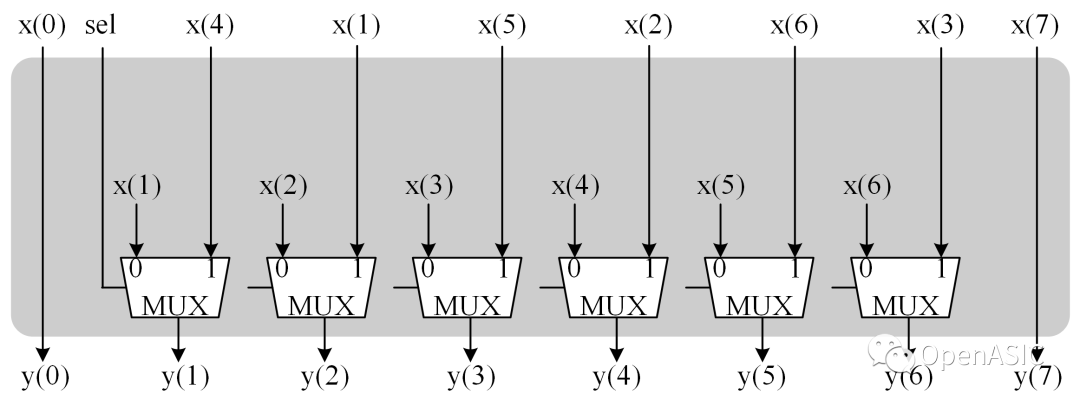
PN*XNT模塊的硬件設計以P8*X8T為例,如下圖所示。
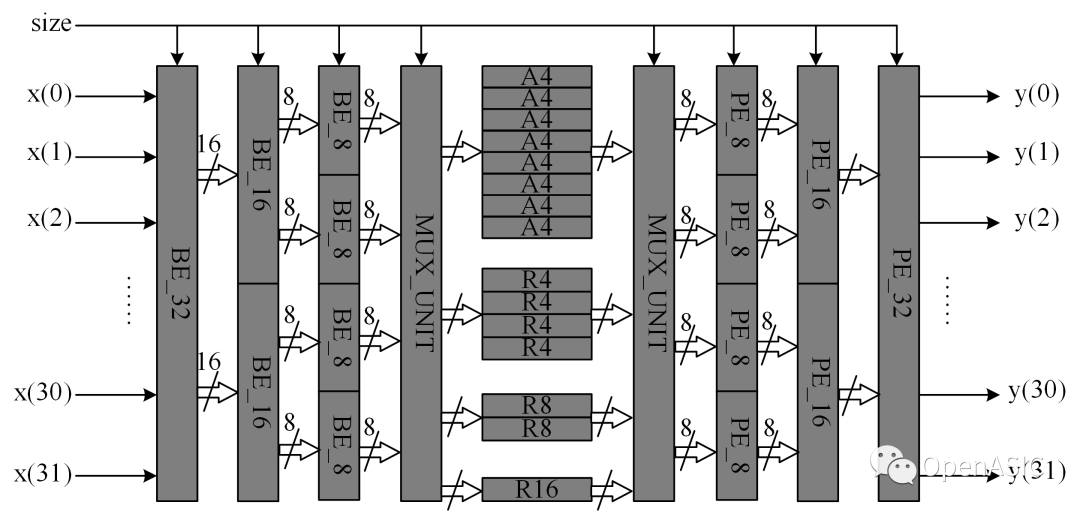
由模塊化的設計方法,可以得到同時支持4點、8點、16點、32點DCT變換的硬件結構。適當地調整算法,可以得到一種吞吐率為32點/周期的結構,該變換結構一個周期可以處理8條4點輸入向量,4條8點輸入向量,2條16點輸入向量,1條32點輸入向量。下圖顯示了固定吞吐率為32點每周期的高吞吐率1D-DCT變換硬件結構。
進一步地,由于1D-DCT和1D-IDCT的計算過程相似,均可分三步進行,但運算過程相反。通過一定的算法改進DCT和IDCT可以用一套硬件實現,相比于分立實現,復用結構可以大大減小硬件開銷。下圖說明了一維DCT模塊在正變換和反變換上的復用。
轉置存儲器
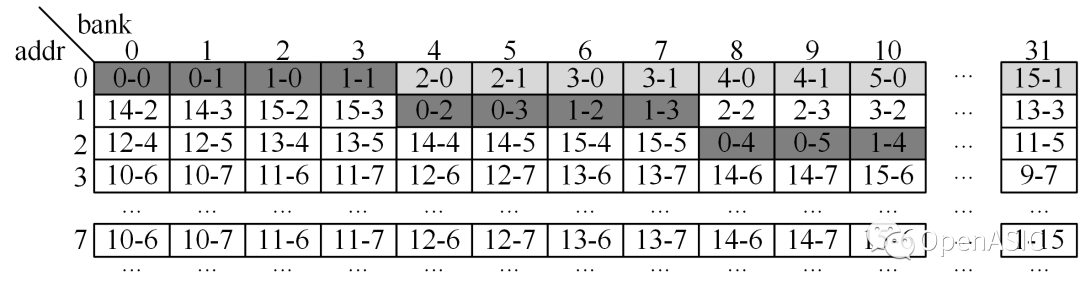
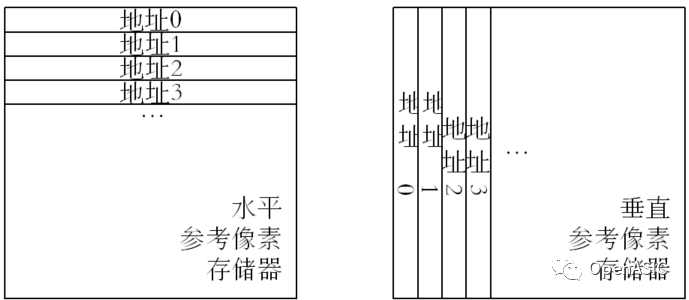
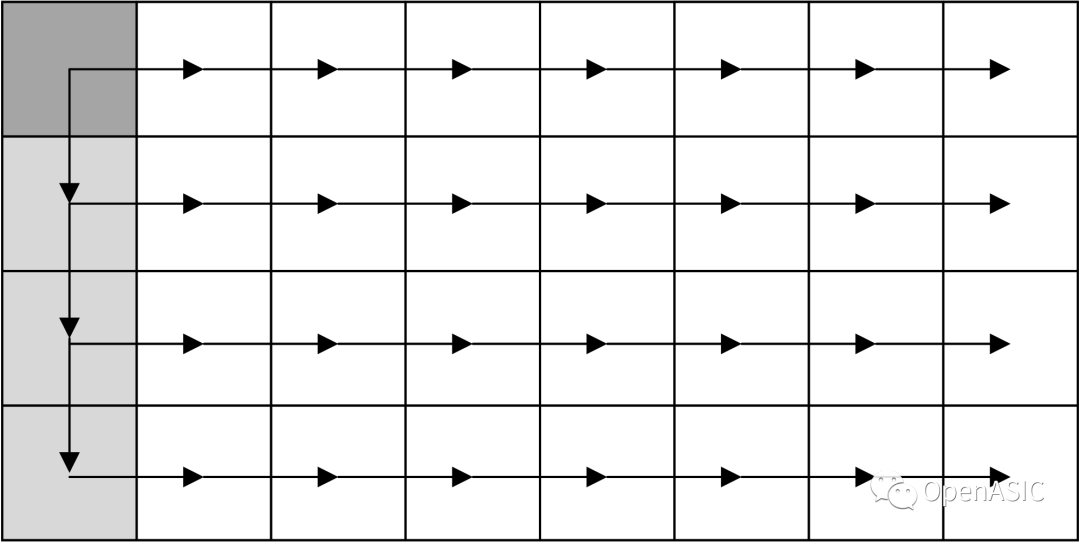
有研究者提出了一種基于單端口SRAM的轉置矩陣的地址映射算法[1]。該結構采用一種對角線螺旋式的數據映射方式,可以實現與TU尺寸大小相等的數據吞吐率,如下圖所示。
為了能夠支持恒定32點每周期的變換/反變換模塊,此處對該映射方法進行了擴展。具體地,在處理32×32大小的TU時,仍然按照上述的方法進行映射。在處理16×16大小的TU時,按照下所示的方式映射,映射到每個bank的前7個地址。
在處理08×08大小的TU時,按照下所示的方式映射,映射到每個bank的前2個地址。
顯然地,在這一方式下,無論是32×32塊,還是16×16塊,亦或8×8塊都能夠滿足32像素每周期的轉置速度。
量化和反量化
量化和反量化的主要運算都是乘法、加法和移位,因此HEVC中量化和反量化的計算可以由統一的公式表示,如下所示:
其中,input表示輸入系數;q表示量化或反量化的系數;offset表示補償量;shift表示移位的比特數;
在量化過程中,參數q=f(QP%6),offset根據RDOQ的開關情況進行調整,shift=21+QP/6-M-(B-8)。
在反量化過程中,參數q=g(QP%6)<<(QP/6),offset=1<<(M-2+(B-8)),shift=1<<(M-1+(B-8))。
由計算過程可知,量化、反量化以及量化與反量化硬件復用模塊的硬件設計均可分為兩部分:參數計算模塊和主體運算模塊。
下圖所示為Q/IQ復用模塊的參數計算單元,輸出為q,offset,shift三個基本參數。輸入為量化步長QP,控制信號CTRL,位深B。
下圖所示為Q/IQ復用結構的主體運算單元,量化與反量化可分為乘,加,移位,截位四部分,為了獲得更高的性能,可以將主體運算單元分兩級流水進行:乘法操作為第一級,加法,移位和截位操作為第二級。
下圖所示為N路并行的Q/IQ硬件復用結構,該結構可以支持N路并行的量化、反量化以及量化與反量化復用的操作。
并發存儲器
對于預測、去方塊化和熵編碼模塊,由于其處理的基本單元是4×4塊,因此,一般采用4×4塊的輸入輸出格式。此處,我們將這種格式稱為塊格式。對于像素讀入,考慮到總線和外部存儲器的突發傳輸特性,像素一般按照光柵順序讀入。此處,我們將這種格式稱為行格式。本文提出的并發存儲器就是為了以極少的資源代價完成對于上述格式的快速轉換。下圖將給出并發存儲器的具體映射方法。
使用并發存儲器,所有左右相鄰的4個1×8行都被映射到了不同的Bank中,因此,不管是1×32,1×16還是1×8都能夠沒有沖突地被訪問;特別地,所有上下相鄰的2個1×16行和相鄰的4個1×8行也被映射到了不同的Bank中,因此,不管是2×16,還是4×8都能夠沒有沖突地被訪問。
架構優化
重建環路多數的周期都被消耗在了4×4大小的TU上,但另一方面,4×4塊變換的復雜度遠比大塊變換簡單得多。因此,本文對4×4專用通路進行了優化。優化后,重建環路的時空圖如下所示。此時,周期數已經減至2880周期。
當重建環路不僅負責PU劃分還負責PU模式的決定時,可以選擇兩種不同的結構。若仍采用全復用的方式,則時空圖如下所示,對應的周期數為9816。
值得注意的是,對于同一塊不同模式的預測是不存在數據依賴的,因此,上圖中對于模式1正向行變換和對于模式0的正向列變換完全可以并行。此時,重建環路的時空圖如下圖所示。采用這一架構后,重建環路在消耗10092周期的情況下所遍歷的模式數高達13個。
資源代價分析
下表給出各個模塊所占用的資源代價。由表可知,未復用前,變換/反變換模塊的ALUT數目高達108713個,優化后ALUT數目減少為47746個,減少了56.08%的資源消耗;未復用前,量化反量化的ALUT數目為11135,優化后ALUT數目減少為6198個,減少了44.34%的資源消耗。



對于全復用結構,其ALUT代價僅為64K,但在500MHz工作頻率下該結構只能夠遍歷所有劃分的5種幀內預測模式;對于半復用結構,其ALUT代價為97K,但在500MHz工作頻率下該結構能夠遍歷所有劃分的13種幀內預測模式。在編碼器實現時,應根據幀內前預測所提供的模式的準確度、系統所需的編碼效果要求和硬件代價要求綜合選擇合適的復用結構。
參考文獻:
[1] S. Shen, W. Shen, Y. Fan and X. Zeng.AUnified 4/8/16/32-Point Integer IDCT Architecture for Multiple Video CodingStandards[A].IEEE International Conference on Multimedia and Expo[C].IEEE,2012:788-793.
模塊用以產生重建后的殘差和重建后的像素_1652346527094.png)