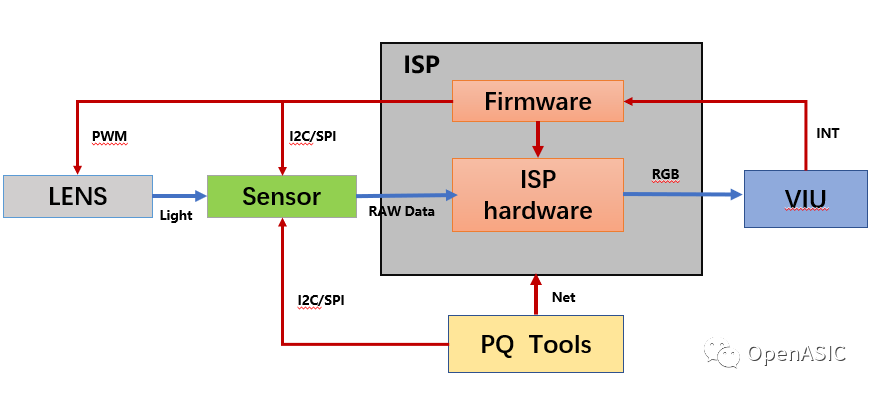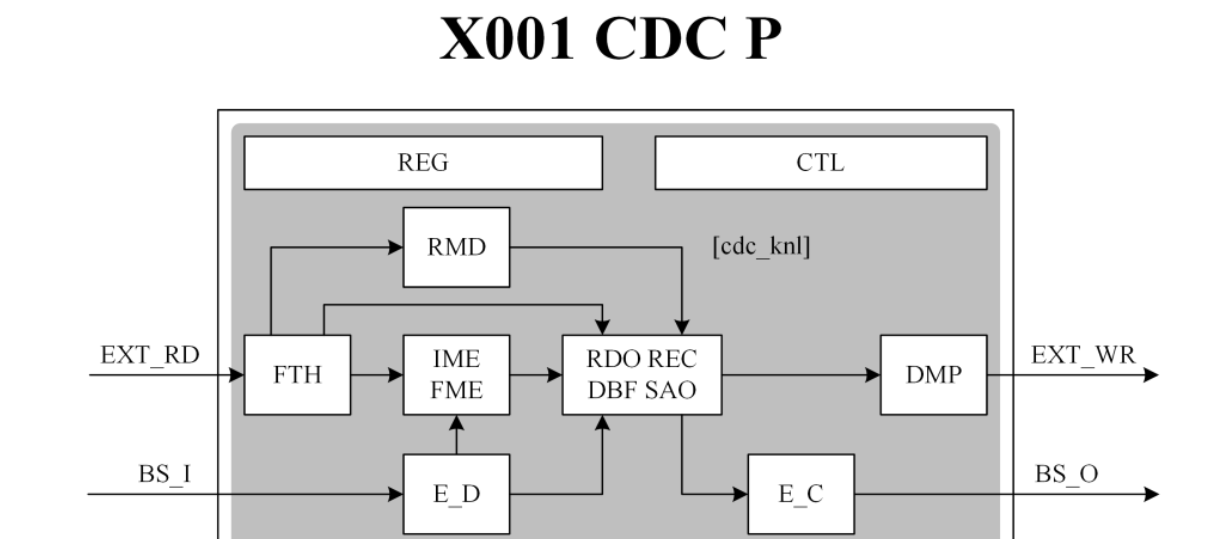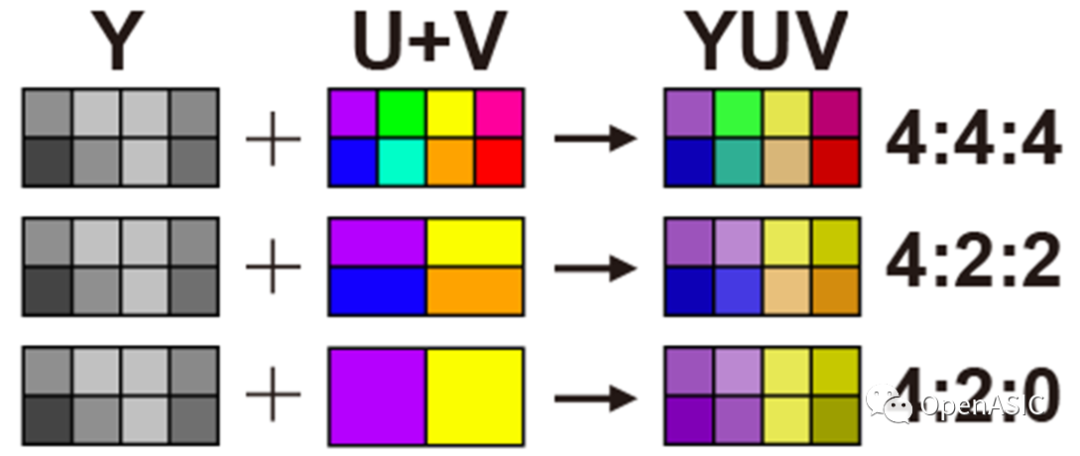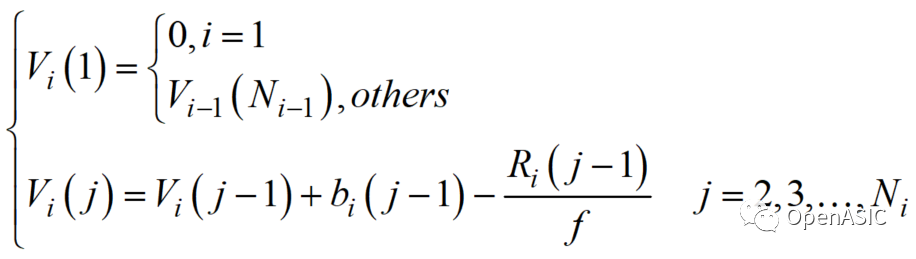
本系列主要介紹視頻編解碼芯片的設計,以HEVC視頻編碼標準為基礎,簡要介紹編解碼芯片的整體硬件架構(gòu)設計以及各核心模塊的算法優(yōu)化與硬件流水線設計。
本文將首先介紹HEVC標準中,分像素運動估計的亮度分量和色度分量的插值方法,以及HM中分像素運動估計的搜索方法。然后,我們提出了一種基于4步搜索策略的分像素運動估計算法和粗略運動向量預測CMVP方法,并進行了對應的FME硬件架構(gòu)設計和VLSI實現(xiàn)。最后,我們對所提出的FME架構(gòu)進行了測試,展示了包括硬件面積和編碼速度在內(nèi)的指標結(jié)果。
概述
自然場景中的圖像一般是模擬和連續(xù)的,圖像中物體的運動也是連續(xù)的。因此運動的偏移也不會是整數(shù)像素的跳躍式運動。因此為了提高預測的準確性,分像素精度的運動估計被引入到視頻壓縮編碼技術中。
1
插值計算
通過各種方式采樣到的視頻,本身并不包含分像素。分像素須由整像素經(jīng)過一定的插值計算才能夠得到。因此在整像素運動估計和分像素運動估計之間,需要在參考幀圖像的搜索范圍內(nèi)進行分像素點的插值計算。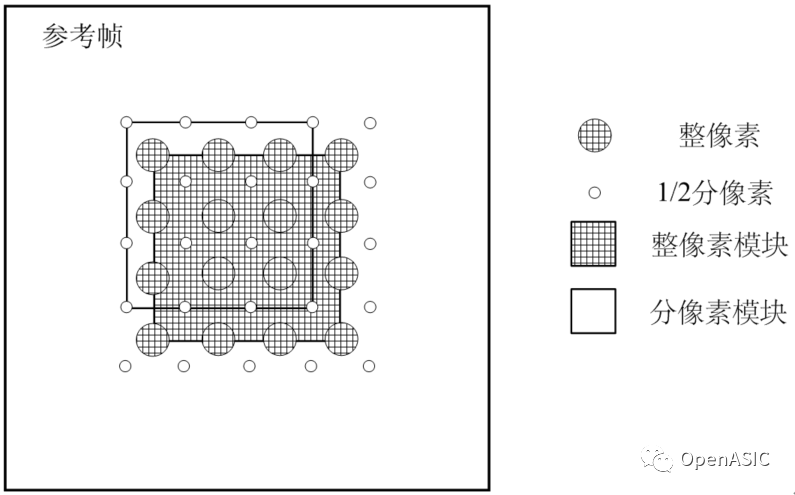
圖1
與H.264/AVC編碼標準類似,在H.265/HEVC標準中,對于視頻序列的亮度(Luma)分量,其分像素運動估計的精度為1/4個像素;相應的,對于YUV 4:2:0視頻序列的色度(Chroma)分量,其分像素運動估計的精度為1/8個像素。但是,相較于H.264/AVC中使用的6抽頭濾波器(用于1/2像素插值)和2抽頭濾波器(用于1/4像素插值),H.265/HEVC使用了更多的鄰近像素用于插值:在1/2亮度像素的插值過程中,HEVC采用了8抽頭濾波器,而在1/4和3/4亮度像素的插值過程中,HEVC采用了7抽頭濾波器;在色度像素的插值過程中,HEVC采用了4抽頭濾波器。亮度插值的對應位置如下圖2所示,其中a和d是1/4精度像素插值位置,b和h是1/2精度像素,c和n是3/4插值位置的像素。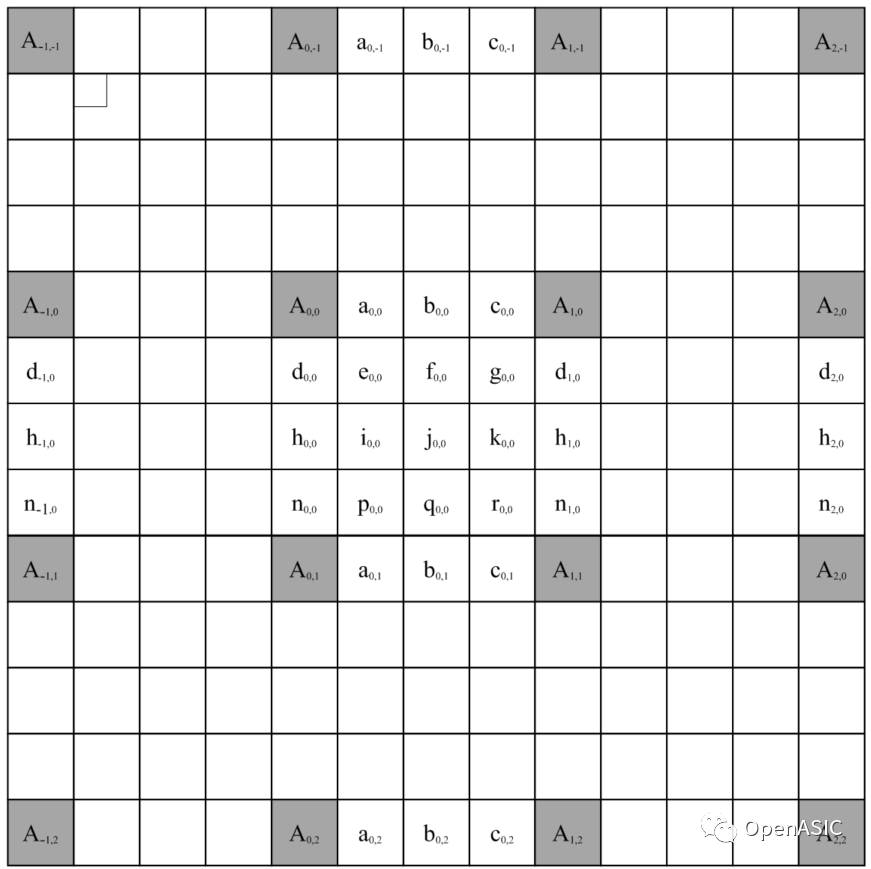
圖2
圖中深灰色的部分是整像素運動估計完成后的整像素點,首先就需要依據(jù)這些整像素點進行插值。不同位置的分像素所用插值濾波器的系數(shù)不同,如下表1所示。
表1
可以發(fā)現(xiàn),分像素位置分為兩種,一種是與整像素點位于同行或者同列的分像素,另一種則是不與整像素同行或者同列的分像素。因此針對這兩種不同的分像素,可分為兩步對它們進行分別插值。
亮度分像素的插值完成后,就要進行色度分像素的插值。色度分像素的插值精度是1/8,因此需要插值的像素會更多,具體位置如下圖3所示。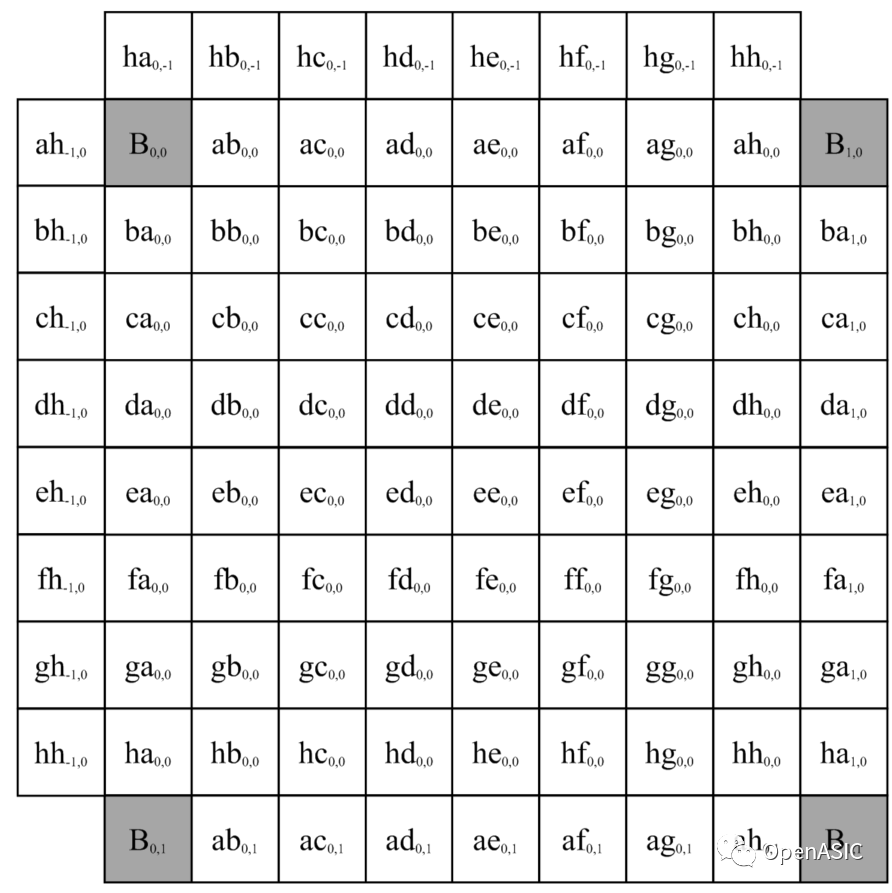
圖3
與亮度分像素的插值十分類似,色度分像素插值也是分為兩步。首先對與整像素點同行同列的分像素點進行插值,然后對其余剩下的分像素點進行插值。色度分像素插值濾波器系數(shù)如下表2所示。
表2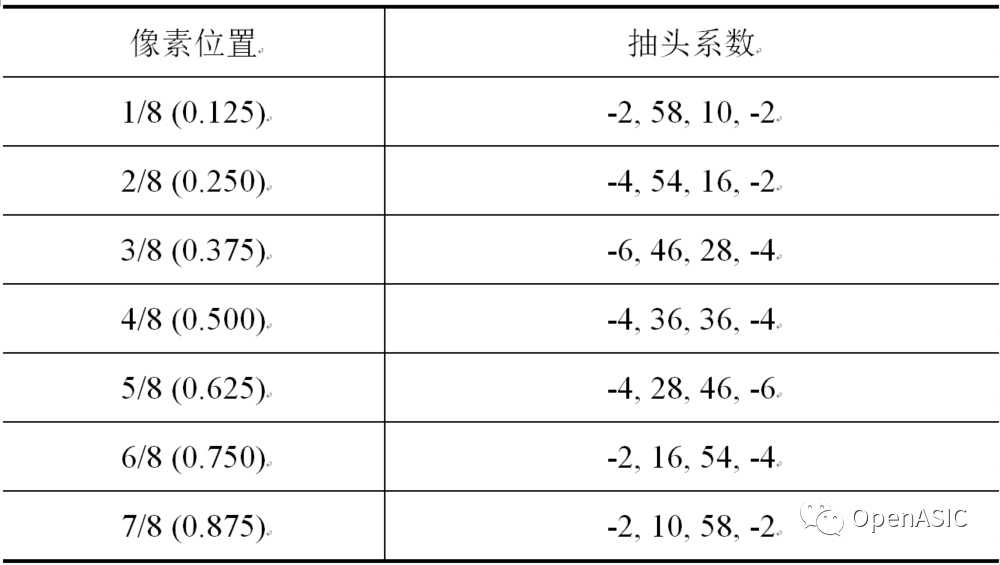
HM中的搜索過程
HM中分像素運動估計采用了兩步搜索法:
(1) 以整像素運動估計搜索出來的最佳整像素運動矢量為中心,得到其附近的8個1/2像素點,并插值得到這8個1/2像素點對應的亞像素參考塊。計算這9個點(8個1/2像素點和1個整像素點)的代價,取代價最小的點作為第1步的最佳亞像素運動矢量。
(2) 以第1步的最佳亞像素運動矢量為中心,得到其附近的8個1/4像素點,并插值得到這8個1/4像素點對應的亞像素參考塊。計算這9個點(8個1/4像素點和1個1/2像素點)的代價,取代價最小的點作為最終的最佳亞像素運動矢量。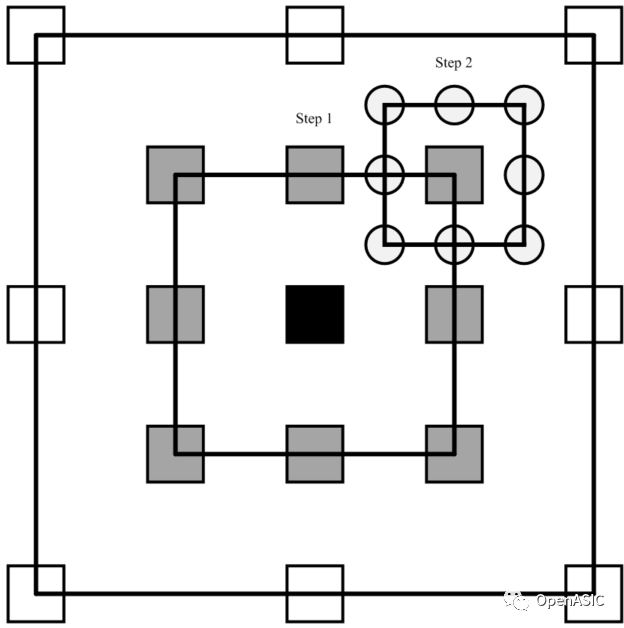
圖4
運動向量預測
HEVC標準提出了Merge模式和AMVP模式,以達到節(jié)約編碼比特數(shù)、提高編碼效率的目的。
在Merge模式下,利用已編碼PU的運動信息為當前PU建立一個候選運動矢量集,其中包含5個候選運動矢量,對其進行遍歷,選擇其中率失真代價最小的一個直接作為當前PU的MV,以此代替當前PU的運動估計過程。這樣大大降低了計算量,且當前PU的MV等于空域或時域上相鄰塊的MV,則不存在MVD,大幅省去了編碼MVD的比特數(shù)。
高級運動向量預測(Advanced Motion Vector Prediction,AMVP)是H.265/HEVC標準提出的一項技術,其基本原理是對于當前正在搜索的預測單元PU,利用其時域和空域鄰近塊的運動矢量,為其建立一個候選預測矢量列表,包含兩個預測運動矢量MVP[0]和MVP[1]。編碼器從其中選擇最優(yōu)的MVP,傳遞給運動估計的模塊作為其搜索的起點;運動估計完成后,得到MV與該MVP的值會非常接近,那么計算出的MVD就會較小,用對MVD進行編碼代替對MV編碼,需要的比特數(shù)將大大減少,由此來提升編碼效率。解碼端會建立同樣的MVP列表,再結(jié)合碼流中讀取的MVD信息,即可恢復出MV。
算法優(yōu)化
搜索方法
在本文提出的分像素運動估計的算法中,我們采用了4步搜索策略:
(1) 以整像素運動估計搜索出來的最佳整像素運動矢量為中心,得到其附近的8個1/2像素候選點,并插值得到這8個1/2像素候選點對應的分像素參考塊。計算這9個候選點(8個1/2像素候選點和1個整像素候選點)的代價,取代價最小的候選點作為第1步的最佳亞像素運動矢量。
(2) 以粗略運動向量預測得到的MVPA(見下圖)為中心,得到其附近的距離為1/4像素的8個候選點,并插值得到這9個候選點(8個周邊候選點和1個MVPA像素點)對應的參考塊。計算這9個候選點的代價,取代價最小的候選點作為第2步的最佳運動矢量。
(3) 以粗略運動向量預測得到的MVPB(見下圖)為中心,得到其附近的距離為1/4像素的8個候選點,并插值得到這9個候選點(8個周邊候選點和1個MVPB像素點)對應的參考塊。計算這9個候選點的代價,取代價最小的候選點作為第3步的最佳運動矢量。
(4) 比較第1步、第2步和第3步的最小代價,得到最終的最佳運動矢量。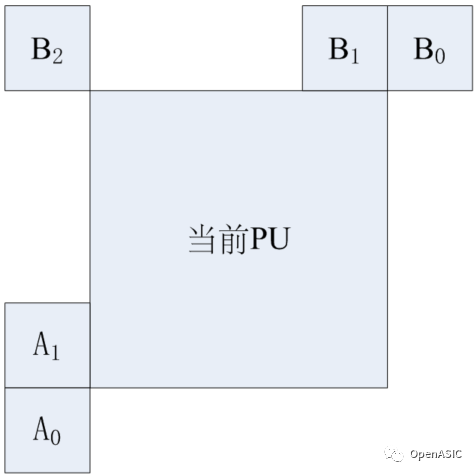
圖5
我們提出的搜索算法檢查了個搜索點,比Lin Y[1](6個)、Chen Y[3](25個)和He G[4](12個)工作中搜索點數(shù)目都要更多。此外,該搜索算法除了檢查了最佳整像素運動矢量附近的亞像素搜索點,還檢查了兩個粗略預測矢量附近的搜索點,也就是說,該算法覆蓋的范圍更廣。
在第2步和第3步中,由于MVPA和MVPB不一定是整像素運動矢量,因此其周圍8個候選點可能為整像素候選點,也有可能是1/2亞像素搜索點或者1/4亞像素搜索點。在本節(jié)搜索算法對應的硬件設計中,1/4亞像素搜索點對應的參考塊并不依賴于1/2亞像素搜索點的插值結(jié)果。我們的設計會增加插值模塊的硬件代價,但也因此能夠支持9個候選點的同時搜索。
粗略運動向量預測
在分像素運動估計的代價估計階段,我們采用了殘差的SATD變換值和MVD的代價之和作為評判標準。但是,在我們的HEVC編碼器硬件設計中,LCU的塊劃分模式在FME后續(xù)的RDO階段才能獲得,所以FME階段沒法得到精確的AMVP結(jié)果。因此,我們提出了粗略運動向量預測方法(Coarse Motion Vector Prediction,CMVP),其基本原理是不考慮LCU的劃分,對于每個PU,其預測矢量為對應位置的8×8塊的最佳運動矢量。
圖6
如上圖6所示,黑色線代表了最終RDO計算得到的塊劃分模式。對于16×16大小的PU塊,其AMVP得到的A0矢量應該是圖中紅色線16×16塊的最佳運動矢量;在本設計的FME中,通過CMVP得到的A0矢量是圖中黃色線8×8塊的最佳運動矢量。考慮到黃色線8×8塊屬于紅色線16×16塊,我們通過該黃色線8×8塊得到的最佳運動矢量應該近似于AMVP中A0矢量的大小。
VLSI實現(xiàn)
硬件設計架構(gòu)
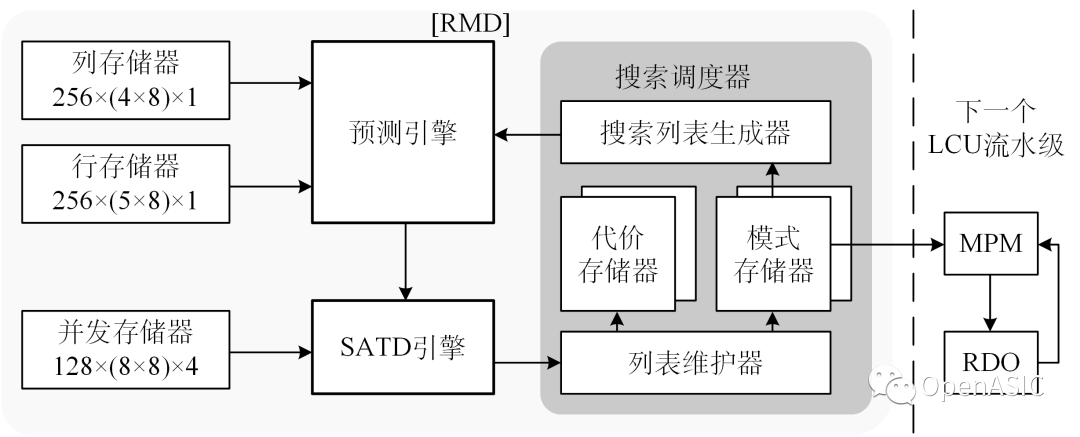
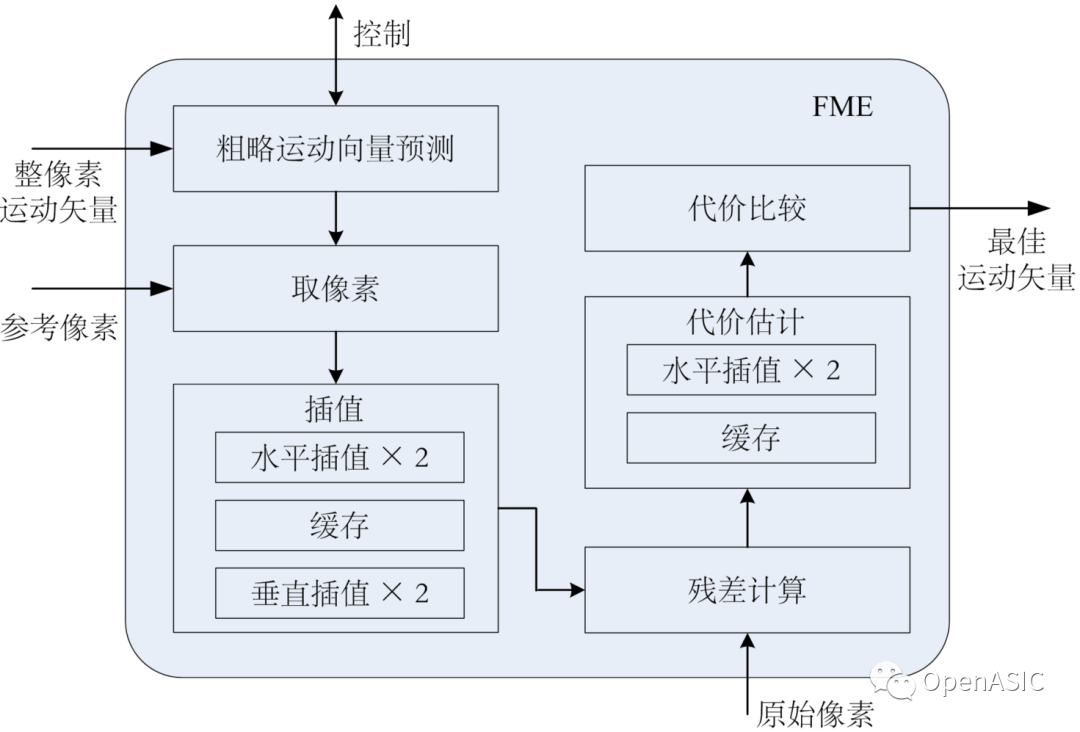
我們提出的分像素運動估計的硬件設計架構(gòu)如下圖7所示。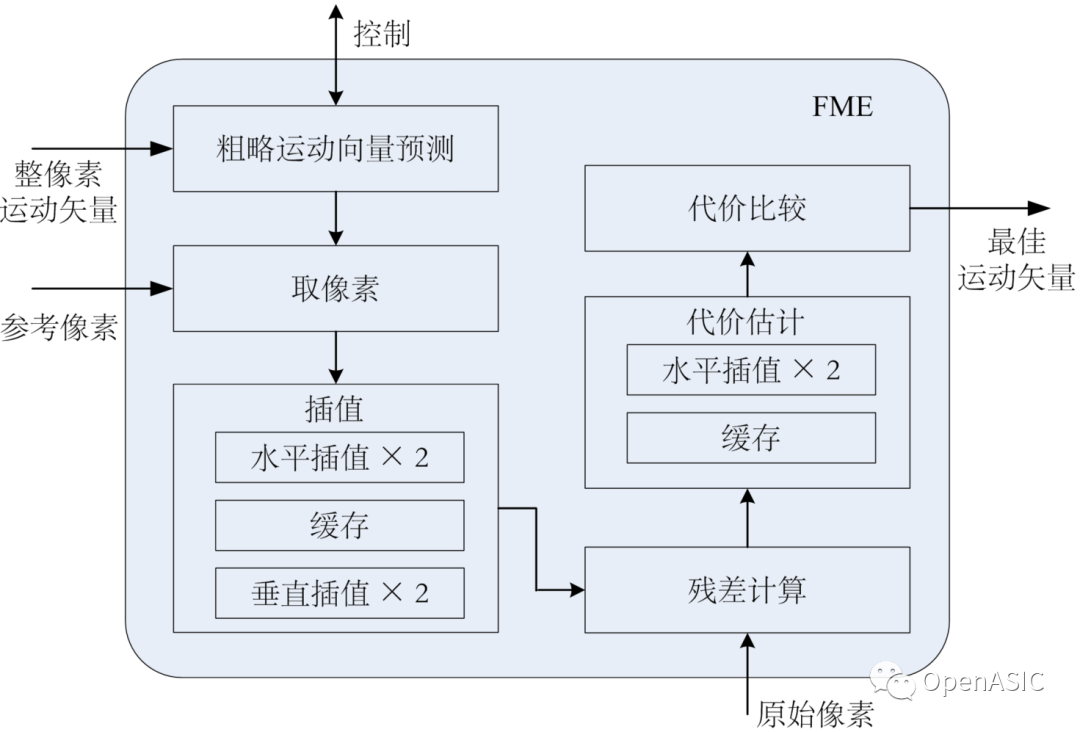
圖7
本文設計的分數(shù)運動估計硬件模塊只檢查2N×2N和N×N的PU塊,且基本處理單元為8×8。對于16×16、32×32和64×64大小的PU,其代價由其下的8×8塊計算求和得到。
(1) 首先,粗略運動向量預測CMVP模塊計算得到MVPA和MVPB,并把當前檢查的搜索中心點送到后續(xù)的取像素模塊。
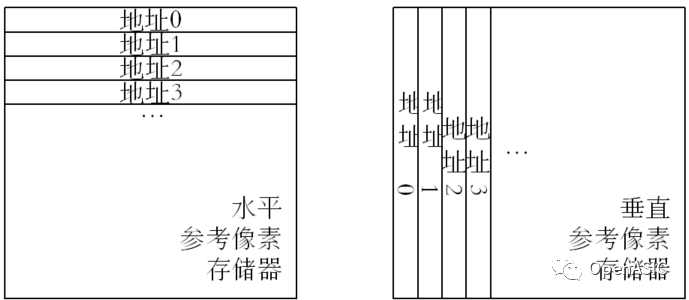
(2) 取像素模塊以當前檢查的搜索中心為中心(IMV、MVPA或者MVPB),從參考像素存儲器讀出16×16大小的參考像素塊。
(3) 插值模塊依次經(jīng)過水平插值、轉(zhuǎn)置和垂直插值,將該搜索中心及其附近8個候選點對應的參考像素塊(合計9個參考像素塊),送到后續(xù)的殘差計算模塊。
(4) 殘差計算單元負責將這9個參考像素塊與原始像素塊做差,得到每個候選點的殘差。
(5) 在代價估計單元中,將對殘差做SATD操作,并對MVD計算代價,得到9個候選點的代價。
(6) 代價比較單元比較這9個候選點的代價,得到最小代價以及相應的最佳亞像素運動矢量。
性能評估
我們提出的分像素運動估計硬件設計的模塊時空圖如下圖8所示,圖中的序號代表該模塊當前正在處理的8×8塊的編號。
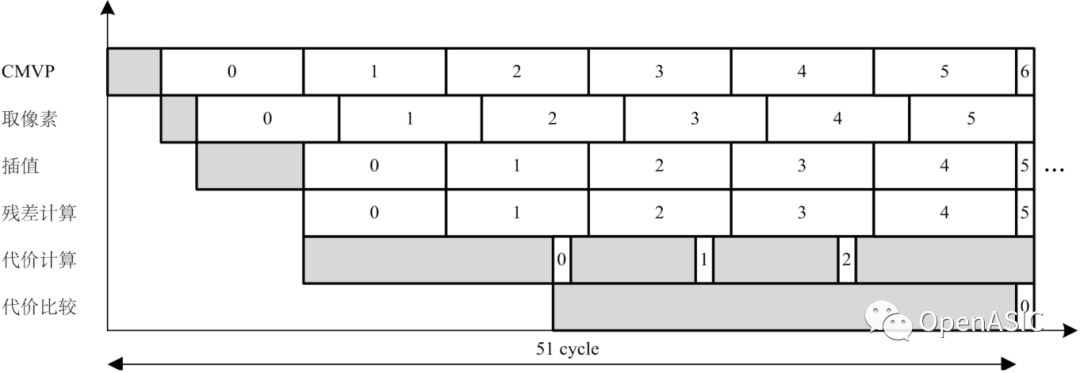
圖8
觀察上圖7可以發(fā)現(xiàn),從開始分像素運動估計到輸出第一個8×8塊的最佳運動矢量需要51個周期,之后每8個周期輸出一個8×8塊的最佳運動矢量。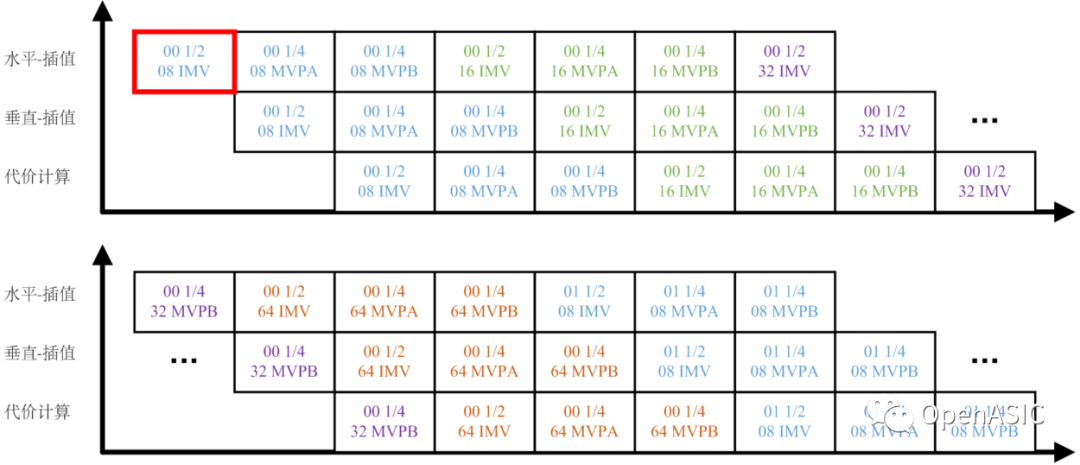
圖9
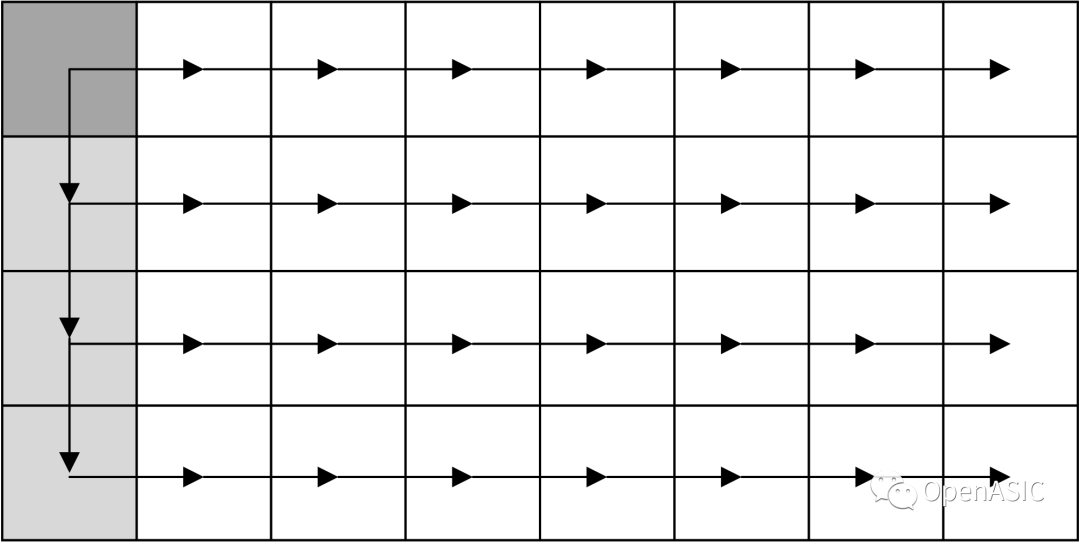
8×8塊的計算順序如上圖9所示。以圖中紅色方框內(nèi)的8×8塊為例:“00”代表該8×8塊水平坐標為0,垂直坐標為0;“1/2”代表周邊候選點距離搜索的中心點的距離為1/2個像素;“08”表示該塊屬于8×8大小的PU;“IMV”代表當前搜索的中心點為整像素運動估計得到的整像素最佳運動矢量。
觀察上圖8可以發(fā)現(xiàn),8×8塊的計算順序為:
(1) 遍歷三個候選的搜索中心:IMV、MVPA和MVPB。
(2) 遍歷該塊所在的各個層次的PU:8×8、16×16、32×32、64x64。
(3) 遍歷LCU塊內(nèi)的所有8×8塊(zig-zag順序)。
因此,本文提出的FME硬件設計的總周期數(shù)約為:
8×3×4×(64×64)/(8×8)+51 = 6195
本文提出的分像素運動估計模塊的工作頻率為500MHz,因此其對UHD 4K×2K分辨率視頻序列的編碼幀率為
500×106/[3840×2160×6195/(64×64)] ≈ 40
下表3給出了本架構(gòu)的硬件代價。其中,插值模塊占據(jù)了68.6%的面積;代價估計模塊占據(jù)了27.4%的面積;其他模塊所占的代價都較小。
表3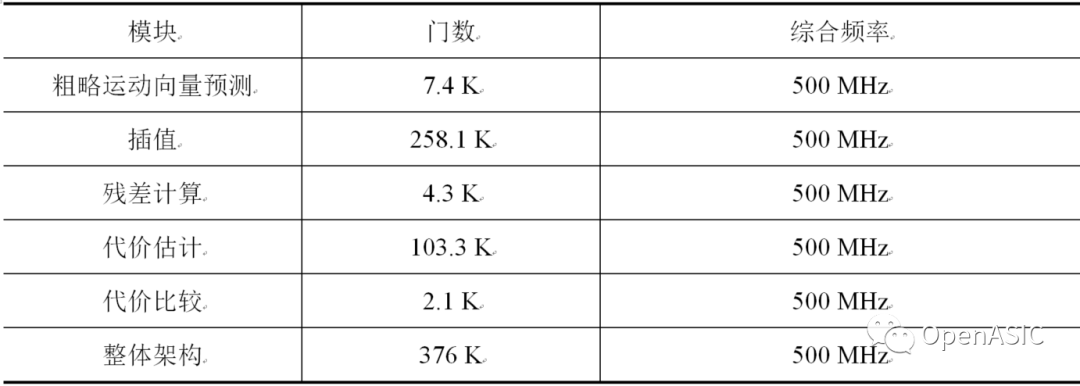
我們對所提出的分像素運動估計架構(gòu)進行了仿真測試,Class A~E的視頻序列均仿真通過。此外,我們將綜合結(jié)果與業(yè)界的相關工作進行了比較,如下表4所示。
表4
在分像素運動估計的搜索候選點方面,我們提出的FME架構(gòu)的搜索點數(shù)達到了27個,是這幾個工作里面最多的。這是因為本節(jié)采用的插值引擎能夠同時支持1/2像素和1/4像素的插值,且1/4像素的插值的不需要依賴1/2像素的插值結(jié)果,因此整個架構(gòu)的吞吐率較高。
在硬件門數(shù)方面,本文提出的FME架構(gòu)比He G[3]的工作要更小,這主要是因為我們提出了相對更簡單的FME搜索算法,且簡化了候選點代價估計的算法。但是,相比較于Lin Y[4]和Kao C[5]的工作,我們提出的FME架構(gòu)硬件門數(shù)要高一些,這是因為我們適用的HEVC編碼器的插值方法比H.264編碼器的插值方法更加復雜。
參考文獻:
[1] Y.-K. Lin,C.-C. Lin, T.-Y. Kuo, and T.-S. Chang. A hardware-efficient H.264/AVCmotion-estimation design for high-definition video [J]. IEEE Transactions onCircuits and Systems I, 2008, 55(6): 1526–1535.
[2] Y. Chen, T.Chen, C. Tsai, S. Tsai and L. Chen. Algorithm and Architecture Design ofPower-Oriented H.264/AVC Baseline Profile Encoder for Portable Devices [J].IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(8):1118-1128.
[3] G. He, D.Zhou, Y. Li, Z. Chen, T. Zhang and S. Goto. High-Throughput Power-EfficientVLSI Architecture of Fractional Motion Estimation for Ultra-HD HEVC VideoEncoding [J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems,2015, 23(12): 3138-3142.
[4] Y. Lin, C. Lin, T. Kuo and T. Chang.A Hardware-EfficientH.264/AVC Motion-Estimation Design for High-Definition Video[J]. IEEETransactions on Circuits and Systems I, 2008, 55(6): 1526-1535.
[5] Kao C Y, Wu C L, Lin Y L. A high-performance three-enginearchitecture for H. 264/AVC fractional motion estimation[J]. IEEE Transactionson Very Large Scale Integration (VLSI) Systems, 2009, 18(4): 662-666.